
XMLをパースする方法に関して追記しました
何故か以前の方法でうまくいかなくなってしまったので、別の方法に切り替えました。うまくいかない人は、以下記事参考にしてみてください。
Kindleの蔵書リストを手に入れたのでデータ分析してみたくなった
Kindleの蔵書リストの入手の仕方という面白い記事をみつけました。
早速Kindleのリストをcsvで入手できました。ただ、入手しただけでは面白くもないので、これを題材にデータ分析してみることにしました。分析はGoogle Colaboratoryで行いました。Google Colabに関して詳しく知りたい方は以下の記事参照ください。
Kindleの蔵書リストをデータ分析した結果
蔵書数
613でした。思ったより少なかったです(1000は超えていると思ってました)。感覚は当てにならないですね。
蔵書リストの入手の仕方の記事書いている人、1万冊超えているって書いてありますけど、どういう買い方をしているんでしょうね。1冊1000円としても1000万円を超えていることになりますが…
年毎の購入数
毎年順調に伸びていっているのが見てとれますね。特に2019年は激しく伸びています。ただ、結構無料の漫画セールとかがあったので、その影響もあったかなとは思います。
今年は途中ですが、去年ほどは多くなさそうですね。
月毎の購入数
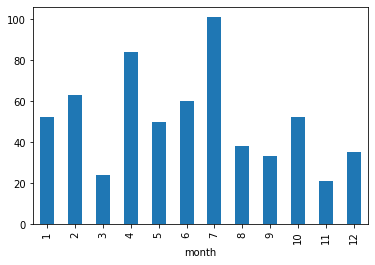
月毎の購入数は、目立った特徴はなかったです。なんとなく年末年始にたくさん買って読んでいる気がしていたのですが、そんなこともなかったですね。
曜日毎の購入数

横軸は0が月曜日で6が日曜日です。やはり休日に買うケースが多いですね。
タイトル文字数の分析
タイトルのヒストグラム
続いてタイトルの文字数を分析してみました。ヒストグラムは以下です。

- 平均:17.693312
- 標準偏差:12.679969
- 最小: 2.000000
- 最大:103.000000
文字数少ないタイトル
文字数の少ない2文字と3文字のタイトルを並べてみました。
- 三体
- 武士道
- 名人伝
- 対話篇
- 山月記
- 武士道
- 黄金虫
名作!という雰囲気を漂わせる本が並びました。
文字数の多いタイトル
逆に文字数多いタイトルを並べてみました。
- [新形式問題対応/音声DL付] TOEICテスト Part 5 できる人、できない人の頭の中 TTTスーパー講師シリーズ
- AIエンジニアを目指す人のための機械学習入門 実装しながらアルゴリズムの流れを学ぶ Software Design plus
- 元Google AdSense担当が教える 本当に稼げるGoogle AdSense 収益・集客が1.5倍Upするプロの技60
- Kindle出版で月20万以上の副業収入を現実的に得る方法: 知識や経験が無くても出版できる!3冊全て1位を獲得した著者が教えるKindle出版副業法
- Minecraft Pi: Making Games Inside a Game: Step-by-Step instructions to make three games in Minecraft Pi
なんというか…ビジネス!って感じのが多いですね。あんまり買った記憶がない本が多いです。多分無料セールとかで買ってしまったのだと思います。
筆者の分析
購入している本が多い筆者の数を並べて見ました。筆者の後ろの数字は、私が持っている書籍の中のその筆者が書いた本の数です。
- 石井 さだよし:58
- 渡辺航:50
- 森博嗣:30
- 三田紀房:22
- デジタルカメラマガジン編集部:13
無料キャンペーンで購入した漫画の作家と、カメラマガジン編集部が並ぶという結果になりました。その中に並ぶ森博嗣先生は凄いですね。森先生は、紙の本も電子書籍以上に持っているので、おそらく紙の本を入れるとブッチギリでトップになると思います。
本記事を参考に試してくださった方々
誰でも簡単にできますので、この記事を読んで興味を持たれた方は是非試してみてください。
試しにやってみた。だんだん読む数は減って来てるのね(だいたい漫画)https://t.co/5zrJPewrYK pic.twitter.com/8XVW9BOUzj
— 渡り鳥🐧 (@wataridori_k) July 19, 2020



まとめ
Kindleの蔵書リストをGoogle Colabでデータ分析してみました。Google ColabのNotebookは、以下のURLで公開します(注:今はうまくいかないかもしれないので、本記事冒頭に追記したリンク先参照ください)。


Googleアカウントさえもっていれば、上記のリンクのNotebookを順にクリックしていけば、誰でもこの記事と同じようなデータ分析ができるようになっていますので、参考にしてみてください。
改めて数字で分析すると、結構自分の感覚とは違うところもあって、数字で把握することの重要さを感じますね。欲を言えば、漫画や実用書というジャンル・本のページ数・出版社の情報とかもあるともっと分析しがいがあるなと感じました。ただ、本のタイトルの情報はあるので、これらの情報を引っ張ってくることもできそうですね。やる気あるかたは、是非そこまで発展させて分析して結果と手順を公開して貰えたら嬉しいです(私が)。
参考リンク






関連記事
変更履歴
- 2021/12/23 XMLをパースする方法に関して追記
- 2020/07/21 本記事を参考に試してくださった方々の情報を追記