Stable Diffusion完全に理解した
画像生成AIで話題のStable Diffusion、完全に理解した状態になりたいですね。私もです。夜な夜な、Stable Diffusion睡眠不足になりながらの自分の理解は以下です。
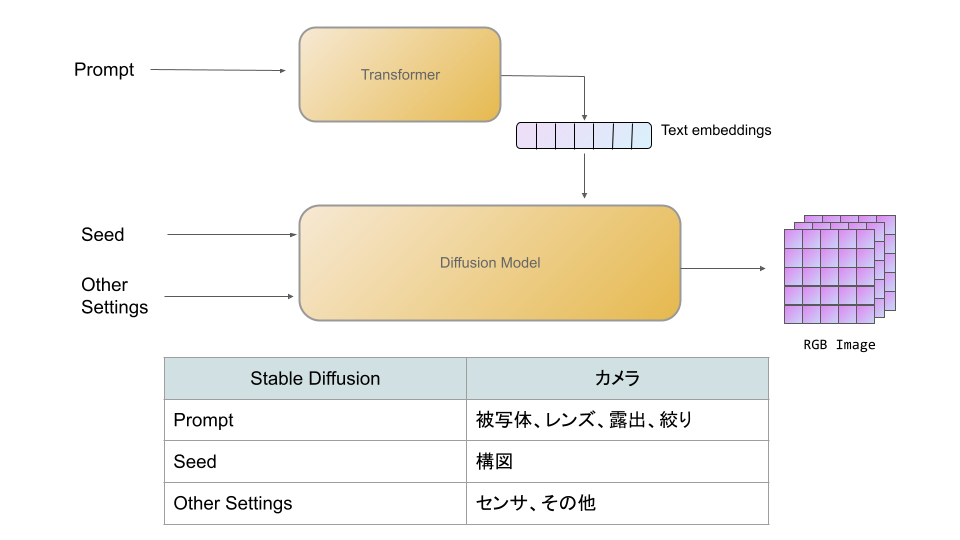
Stable DiffusionというAIモデルは、上記のように、2つのモデルで構成されています。凄いのがDiffusion Modelとよばれるもので、これはランダムノイズ的な画像から、クオリティの高い絵を生成することができます。
ただ、このままだとどんな絵が生成されるか分からないので、絵をコントロールするために、プロンプト(自然言語)をCLIPと呼ばれるTransformerのモデルに入力して、埋め込みベクトルに変換します。このベクトル情報をDiffusion Modelに入れてやることで、自分の好きな画像を生成することができます。
無理やりカメラとの対応を記載した表をつけてみました。PromptとSeedという2つのデータで、カメラにとって重要な要素をかなりコントロールできることが分かります。
もう少し詳しく書いた図は以下になります。

論文に書いてあったり、ネットの情報をもとに自分なりに描きました。詳しくは、またいずれ。
まずはStable Diffusion体験
何はともあれ、まずは体験ですね。おすすめは、AI研究者のshi3zさんが開発したWebサービス Memeplexです。Googleアカウントさえあれば無料で手軽に使用できます。
自分でもっとカスタムしたいという人は、私が作成した以下のGoogle Colabのノートブックを使用してみてください。
ネットの情報を追いたい
毎日画像生成AIの話題を追い続けて提供している凄まじいサイトです。これを読んでおければだいたいトレンドはおさえられると思います。たまに自分の記事が載っていて「おっ!?」となります。
私の個人的なメモです。最近追いつけてないですし、説明もなく雑多にリンクが貼ってあるだけですが、よろしければどうぞ。
より詳細を知りたい
技術同人誌
tomo_makesさんが衝撃のスピードで技術同人誌を作成しています。
特に、Stable Diffusionで重要な画像を生成するDiffusion Modelの動き、特にStable Diffisionで使われているLatent diffusionという技術に関して、手を動かしながら詳しく知りたい人は、これを読むのが一番です。
私も上記の本からリンクされているGoogle Colabのノートブックを読むことで、完全理解した気分になりました。
白金鉱業fm(音声配信)
データサイエンス事業をいとなむ、ブレインパッド社有志の音声配信番組です。


ある程度機械学習の知識がある人向けにはなりますが、めちゃくちゃ分かりやすくStable Diffusionモデルに関して解説してくれています。さすが本職です。
Diffusion Modelの仕組み「この仕組でなぜ画像が生成できるのか分からない、キツネにつままれた気がする」と語っていたのが、印象的でした。本職の人でも同じこと思うんだと、ちょっとだけホッとしました(笑)
Vision Transformer入門
プロンプトを解釈するAIモデルに使われているTransformerを理解するのにピッタリの書籍です。タイミングよく献本いただきました。

共著者に @sei_shinagawa さんが名を連ねる「Vision Transformer入門」献本いただきました!
— からあげ (@karaage0703) September 16, 2022
Transformerは、今気になっている #stablediffusion にも使われているので非常にタイムリーで嬉しいです!
読み始めていますが、序盤の説明がめちゃ分かりやすいです!https://t.co/pHyuTkRP5q pic.twitter.com/gi7HDNuvQv
商業誌のため、さすがにtext-to-imageでの画像生成部分に関しては少し触れられている程度ですが、プロンプトを解釈するAIの基礎技術となるTransformerの仕組みに興味ある人にとって参考になる内容ではないかと思います。ただ、やっぱり一番この本がぴったりな人は画像認識にTransformerを使いたい人ですね。両方興味あるならなおさらGoodです。
著者視点での書評は以下になります。購入悩んでいる方はこちらも参照ください。
拡散モデル データ生成技術の数理

PFN創業者、岡野原さんが拡散モデルに関して書いた書籍。まだ読み始めたばかりなので、また別途レビューを書きますが、間違いなく重要となる一冊です。
お知らせ:YouTube Liveします
というわけ(?)で、本日9/23(金) 21:30頃 (追記:明日 9/24(土) 14:00からに変更します)まったりStable Diffusionでお絵かきしながら語るYouTube Liveでもしようかなと思っていますので、お時間ある方はお付き合いいただけると幸いです。基本は初心者向けですが、ハードコアな話もしてみようかなと思っています。YouTubeは以下です。
Twitterを追っていただければ、最新の配信予定を確認できるかと思いますので、よろしければどうぞ。
9/24(土) 14:00~でYouTube Live配信予約しました > Stable Diffusionの謎 Vol.1 https://t.co/QvKXy0zfL7
— からあげ (@karaage0703) September 23, 2022
まとめ
Stable Diffusion関係に役立つ情報をまとめてみました。正直、AIでお絵かきするだけなら、別に仕組みとか知らなくても全然描けます。カメラに詳しくなくても、上手な写真を撮れる人がいるのと同じですね。むしろ、カメラに詳しいけど、あんまり写真うまくない人って結構いたりします(自分もどちらかというとそのタイプです)。
ただ、Stable Diffusionのような仕組みもAIモデルも公開されているAIに関しては、カメラ以上に中身を知って使いこなすと、AIを知っているからこそできる表現が広がるかなと思いますので、興味ある人は、色々調べてみるのがオススメです。例えば、単純にプロンプトの入力、前から75トークン(意味ある単語の単位)分までしか入力できないという事実を知っているだけでも、無駄に長文を打ち込む必要がなくなるので役に立つかなと思います。このことについては記事書いたりしました。
参考リンク


関連記事
変更履歴
- 2023/02/23 拡散モデルの書籍に関して追記
- 2022/09/23 白金鉱業fm に関して追記